
ChIPseq data mining with ChIPseeker
ChIP-seq is rapidly becoming a common technique and there are a large number of dataset available in the public domain. Results from individual experiments provide a limited understanding of chromatin interactions, as there is many factors cooperate to regulate transcription. Unlike other tools that designed for single dataset, ChIPseeker is designed for comparing profiles of ChIP-seq datasets at different levels.
We provide functions to compare profiles of peaks binding to TSS regions, annotation, and enriched functional profiles. More importantly, ChIPseeker incorporates statistical testing of co-occurrence of different ChIP-seq datasets and can be used to identify co-factors.
> library(ChIPseeker)
> ff=getSampleFiles()
> x = enrichPeakOverlap(ff[[5]], unlist(ff[1:4]), nShuffle=10000, pAdjustMethod="BH", chainFile=NULL)
>> permutation test of peak overlap... 2015-09-24 14:23:43
|======================================================================| 100%
> x
qSample
ARmo_0M GSM1295077_CBX7_BF_ChipSeq_mergedReps_peaks.bed.gz
ARmo_1nM GSM1295077_CBX7_BF_ChipSeq_mergedReps_peaks.bed.gz
ARmo_100nM GSM1295077_CBX7_BF_ChipSeq_mergedReps_peaks.bed.gz
CBX6_BF GSM1295077_CBX7_BF_ChipSeq_mergedReps_peaks.bed.gz
tSample qLen tLen N_OL
ARmo_0M GSM1174480_ARmo_0M_peaks.bed.gz 1663 812 0
ARmo_1nM GSM1174481_ARmo_1nM_peaks.bed.gz 1663 2296 8
ARmo_100nM GSM1174482_ARmo_100nM_peaks.bed.gz 1663 1359 3
CBX6_BF GSM1295076_CBX6_BF_ChipSeq_mergedReps_peaks.bed.gz 1663 1331 968
pvalue p.adjust
ARmo_0M 0.88901110 0.88901110
ARmo_1nM 0.15118488 0.30236976
ARmo_100nM 0.37296270 0.49728360
CBX6_BF 0.00009999 0.00039996
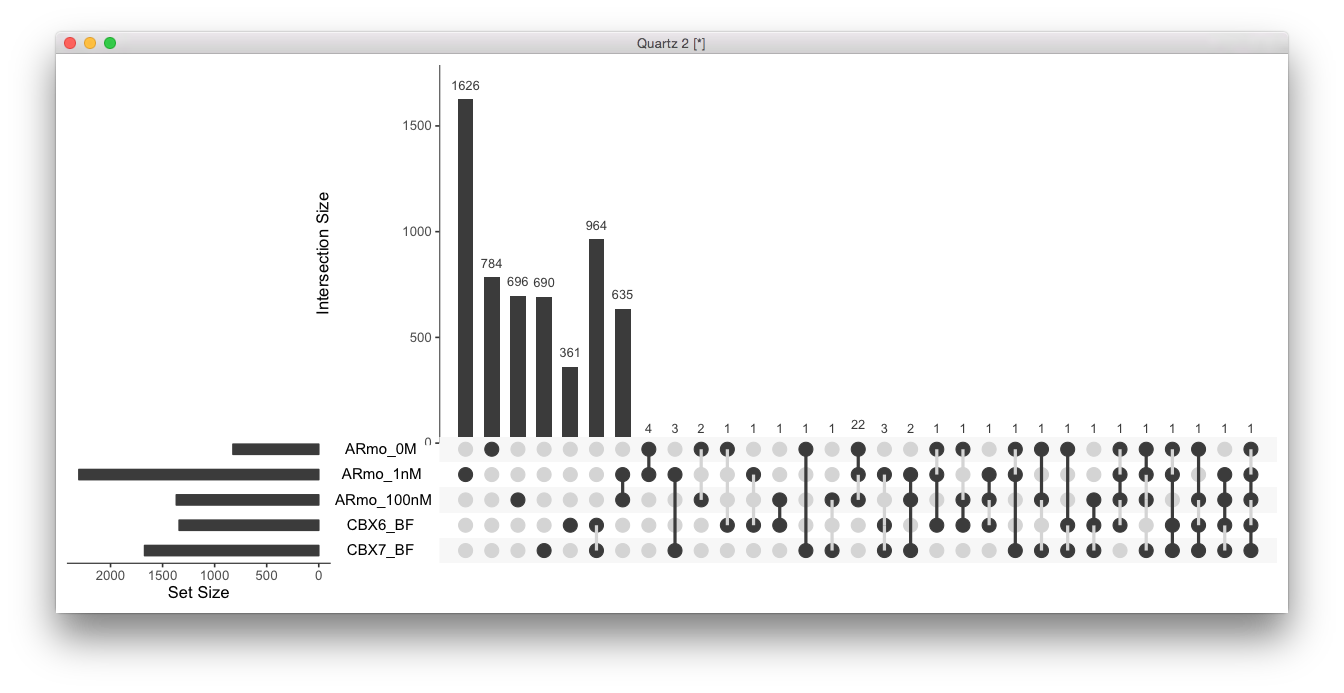
The enrichment analysis of peak overlap is based on permutation test. nShuffle of random ChIP data were generated to estimate the background null distribution of the overlap and p-value is then calculated by the probability of observing more extreme overlap. Multiple comparison correction is also incorporated.
The most exciting feature in ChIPseeker is that it collected more than 18,000 bed file information from GEO database and make this co-factor inference available to the community. With these datasets, we can compare our own dataset to those deposited in GEO to identify co-occurrence binding proteins that maybe cooperated with the one we are interested in. Hypothesis can be generated by this inference and serve as a starting point for further study.
Reference
G Yu, LG Wang, QY He. ChIPseeker: an R/Bioconductor package for ChIP peak annotation, comparison and visualization. Bioinformatics. 2015, 31(14):2382-2383. PMID:25765347.
