4月3号发了以下一条文字推送:
遇到辣鸡导师,只有三个字,忍滚狠,我选择滚,考博期间,发现人品不好,我选择滚,《来香港读博其实是被逼的》,读博期间,本着就是退学也要滚的心态,把导师给炒了,《CS10: 八卦终结版》,忍下来也会消磨掉你所有追求/理想,比狠的话,如果没有压制对方的渠道,对于这种势力严重不均衡的情况似乎不太现实,所以我奉劝大家,滚!一两年的沉没时间,放长远了看,根本不算什么,要勇于放弃,滚的远远的

4月3号发了以下一条文字推送:
遇到辣鸡导师,只有三个字,忍滚狠,我选择滚,考博期间,发现人品不好,我选择滚,《来香港读博其实是被逼的》,读博期间,本着就是退学也要滚的心态,把导师给炒了,《CS10: 八卦终结版》,忍下来也会消磨掉你所有追求/理想,比狠的话,如果没有压制对方的渠道,对于这种势力严重不均衡的情况似乎不太现实,所以我奉劝大家,滚!一两年的沉没时间,放长远了看,根本不算什么,要勇于放弃,滚的远远的
使用barplot来展示富集分析结果是很常用的,而dotplot比较barplot来说,多了一个点大小的信息,可以比barplot展示多一个信息,所以是比较推荐的,我之前已经写了《dotplot展示富集分析结果》和《dotplot for GSEA》两篇文章,dotplot虽然简单,很多人会觉得会容易用ggplot2画出来,但其实有些细节,比如《为什么画出来的点比指定的数目要多?》,有些技巧,比如《搞大你的点,让我们画真正的气泡图》,是很多新手所不具备的,图虽然简单,但老司机的飚车技能也不可小看哦,所以我在《听说你也在画dotplot,但是我不服!》的文后就说了一句话:
clusterProfiler之所以好,因为真的考虑了很多细节!请放开那图,让clusterProfiler来画!
在《你所不知道的,R的N种打开方式》我介绍了N多种打开R的方式,甚至于你还能用python写的号称21世纪的R界面:《R,python喊你回家吃饭啦》。
我自己一直很少用RStudio,而是用Emacs,虽然Emacs比较小众,也不适合这个公众号的粉丝,但文本编辑器之于程序程好比剑客手中的剑,一个用着顺手、长期使用的文本编辑器比什么都好,在《你所不知道的,R的N种打开方式》中我介绍了Emacs, Vim, textMate, sublime,今天要介绍另一款,VSCode,这是微软开源的文本编辑器,非常现代化,有很好的扩展生态。
这是小伙伴的命题作文,下面这个数据是曾老湿给出来的,其中header行竟然放在了最后一行,我手工把它挪到了第一行,里面还有一个数据缺失的,会导致读了数据后会有NA值,需要去除。
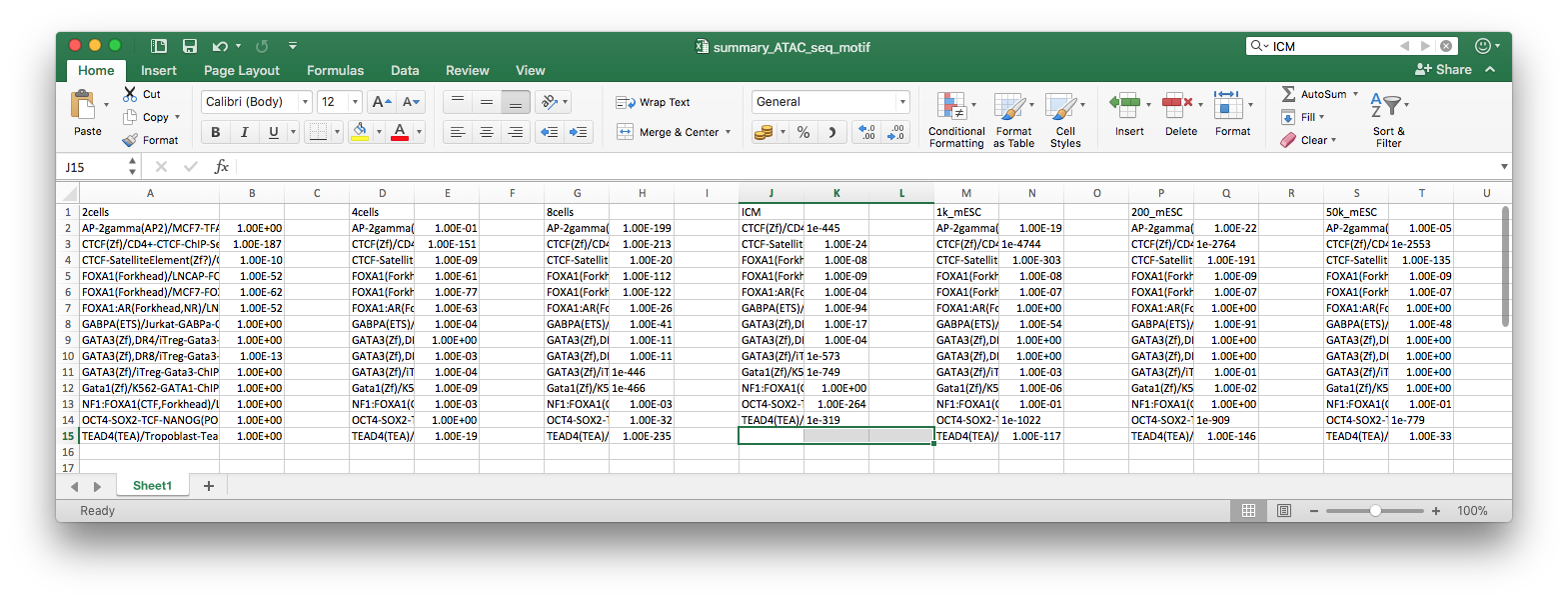
$ file summary_ATAC_seq_motif.xlsx
summary_ATAC_seq_motif.xlsx: Microsoft Excel 2007+
这是一个Excel文件,我们可以用readxl来读:
require(readxl)
x <- read_xlsx("summary_ATAC_seq_motif.xlsx")
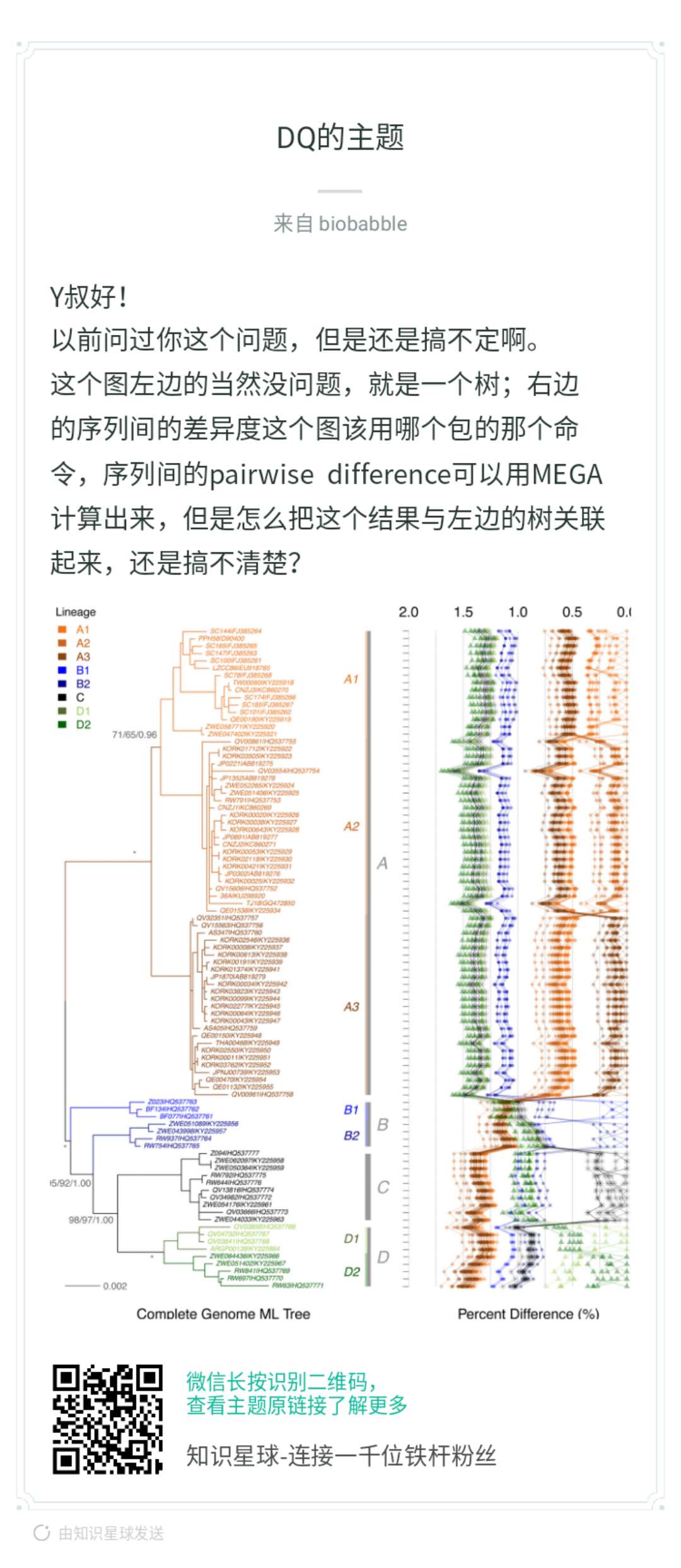
当然是ggplot2画,才好和ggtree兼容,你首先问自己,抛开树,你能右边吗?本身你有个矩阵,row的顺序要跟着树来,你可以先不管,先随意,这是y轴。那x轴呢?你矩阵里的数字,打点你总该会的,而点连线,同样column的数字打出来的点,就连在一起,你先按这个思路画出来,再来问后续的。
这是我在「知识星球」中的回答,然而小伙伴表示还是不懂。那么我来详细讲解一下:
首先我们读入一个FASTA数据:
require(treeio)
fasta <- system.file("examples/FluA_H3_AA.fas", package="ggtree")
aa <- read.fasta(fasta)
数据用treeio包里的read.fasta去读这个氨基酸序列,它有个好处是你直接as.character(aa[[i]])就是个字母的向量,方便比较。
n = length(aa)
d = matrix(NA, ncol=n, nrow=n)
nm = labels(aa)
rownames(d) = colnames(d) = nm
for (i in seq_len(n)) {
for (j in seq_len(i)) {
d[i, j] = mean(as.character(aa[[i]]) != as.character(aa[[j]]))
d[j, i] = d[i, j]
}
}
这段代码生成了pairwise distance矩阵,你可以搞其它的统计量,都OK的。大家可以想一想,一般这种矩阵怎么可视化?用热图!热图用数字来填充颜色,而现在我们把数字当成x轴上的变量,然后打点,仅此而已,我们有没有办法画出来,当然可以。同样row的数值会在同一y轴上,如果是热图,同一column的数值会在同一x轴上,方便横向和纵向比较,而现在同一column的数值不在同一直线一了,因为我们打的点的位置使用了矩阵中的数值,同一column的点被拉扯到不同的位置上去了,所以为了能够比较或者是看清楚同一column上的点的走势,我们把同一column上的点用线条连接在一起。这就是小伙伴提问的图,就是这么画出来的,非常简单。我在「知识星球」里其实已经解答得很清楚了。
小伙伴说他写个CSV文件,名字就变了,无缘无故|就被改了,还有些名字被强加了X。我注意到了他写的对象是data.frame(d),这锅绝对是data.frame的。
我们可以试一下:
> d = matrix(rnorm(4), ncol=2)
> colnames(d) = c("A|B", "123")
> write.csv(data.frame(d))
"","A.B","X123"
"1",-0.601247669017546,0.802654193340092
"2",-0.128752028398414,0.430829592244036
没错,自己给变了。
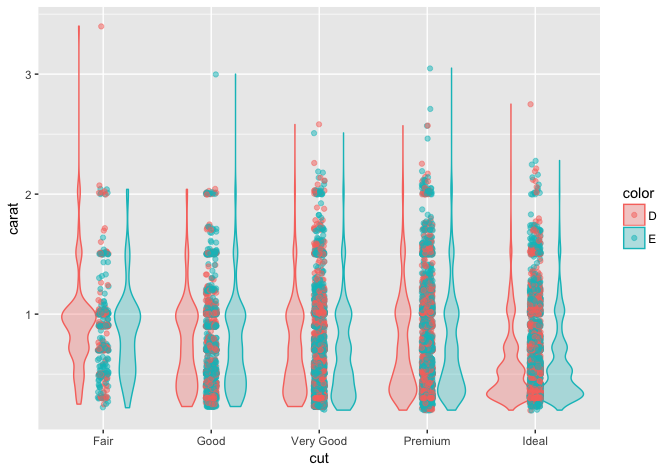
小伙伴提出了上面的问题,点不能够打到violin里面去,即使加了aes(group=color)强行分组也不行。这个照理第一感觉都会觉得可以,但试一下都会发现不行。
library(ggplot2)
d = subset(diamonds, color %in% c("D", "E"))
ggplot(d, aes(cut, carat, fill=color, color=color)) +
geom_violin(alpha=.3) + geom_jitter(width=.05, alpha=.5)