Chapter 2 Substitution and site models
2.1 Jukes-Cantor Model
Jukes-Cantor Model假设一个核苷酸突变为另一个核苷酸的概率是一样的,用\(\mu\)表示。
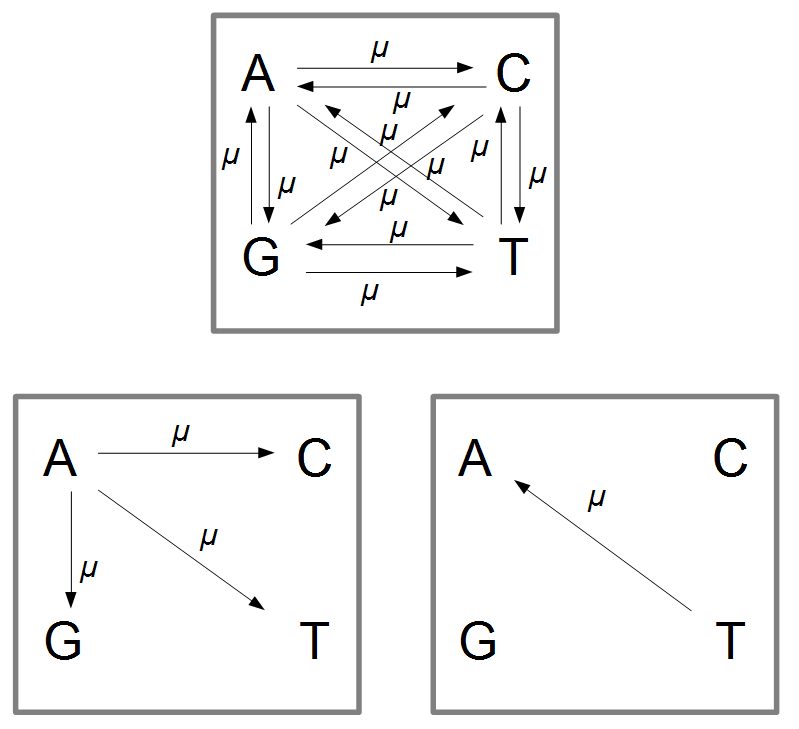
从A突变为其它状态的概率是\(3\mu\),而由其它状态比如说T突变为A的概率是\(\mu\),同样T以同样的概率可以突变为G或C。
一个状态的平衡频率(equilibrium frequency)指突变为这个状态的频率除以所有突变频率的总和,以上面A为例,突变为A的频率是\(\mu\),而A突变为其它的频率是\(3\mu\),也就是说A的平衡频率是\(\frac{\mu}{(3\mu + \mu)}\)也就是1/4,也就是说如果突变在所以情况下概率都一样,那么有25%的可能性A还是A,这个是make sense的,毕竟只有4种状态。
如果我们看所有的突变可能性,变为A状态的途径有3,而总途径是12,我们观察到A的可能性也是1/4。
Poisson分布适合于描述单位时间内随机事件发生的次数的概率分布,在给定事件发生的期望值\(\lambda\)的情况下,可以计算事件发生次数\(k\)的概率:
\(P(k|\lambda) = \frac{\lambda^ke^{-\lambda}}{k!}\)
当\(k=0\)的时候,\(P(0|\lambda) = e^{-\lambda}\)
那么非0事件的概率就是:
\(P(\neg 0|\lambda) = 1 - P(0|\lambda) = 1- e^{-\lambda}\)
回到突变上,我们期望在某个时间区间有一些突变发生,那么我们可以用突变概率\(\mu\)乘以时间\(t\)得到这个期望值。从某个位点出发,有3种可能的突变途径,所以突变概率是\(3\mu\)。
在数学上我们可以把突变当成是4个字母随机抽样,这样子每个字母被抽到的概率都是1/4,然而比如说变为G的概率是1/4,这是不对的,因为如果原先的状态就是G,那么G是不能变为G的,它不是一个突变,为了在数学上更为方便,我们允许一个状态可以「突变」为它自己:
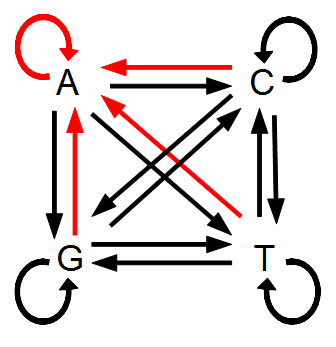
那么在单位时间上的突变概率就是\(4\mu\)。既而Possion的均值就是\(\lambda = 4\mu t\)。
事实上我们比较的是当前的序列,而这些序列都是从共同祖先突变而来,所以实际上的距离是2倍的时间,也就是\(\lambda = 8\mu t\).

所以两个序列的DNA位点没有突变的概率是:
\(P(0|\mu, t) = e^{-8\mu t}\)
而至少有一个突变是:
\(1 - P(0|\mu, t) = 1 - e^{-8\mu t}\)
假如至少有一个突变,而最终突变为某个状态,比如说T的概率1/4,假如最初状态是A的话,那么:
\(P(T|A, \mu, t) = \frac{1}{4}(1 - e^{-8\mu t})\)
实际上A变回A也是同样的概率:
\(P(A|A, \mu, t) = \frac{1}{4}(1 - e^{-8\mu t})\)
那么两个序列同样的位点不一样的概率就是:
\(P(difference|\mu, t) = \frac{3}{4}(1 - e^{-8\mu t})\)
因为一个序列在某个位点的状态有3种可能的不同状态,而这需要发生至少一次的突变。
当t越来越大的时候,\(e^{-8\mu t}\)会越来越小,那么不同状态的概率就会等于3/4,也就是说当两条序列在最初是一模一样的情况下,我们所以观察到最大的不同就是饱和状态的75%。也就是说随机产生的两条序列,也会有25%的位点是一致的,毕竟是从4种核苷酸中抽样产生的。
那么我们期望的距离,核苷酸不一样的频率是:
\(d = \frac{3}{4}(1 - e^{-8\mu t})\)
这个\(d\)我们可以通过计算不同的位点数目除以序列长度得到(p-distance),它会饱和效应,会低估实际的突变。而我们想要的是可以允许我们在时间在尺度上,线性地比较不同的序列,我们所需要的实际上是\(D = \mu t\),代入上面的公式,可以得到:
\(D = -\frac{1}{8}ln(1 - \frac{4}{3}d)\)
这个JC distance,我们会看不到同的版本,主要是不同的scale的问题,比如可以把所有的突变概率除以3(\(\mu/3\)),这样一个碱基突变为其它碱基的概率为\(\mu\),那么:
\(D = -\frac{3}{8}ln(1 - \frac{4}{3}d)\)
另一版本是不考虑2倍时间,而单纯考虑一个序列从祖先序列突变而来,那么:
\(D = -\frac{3}{4}ln(1 - \frac{4}{3}d)\)
这个版本就是最为常见的版本,在这个推导过程中,我们允许了「突变」可以变成自身的状态,这实际上是不符合突变的定义的。所以实际是我们应该只计算突变为不同状态,那么我们应该乘以3/4,以\(\mu/3\)为突变概率,使用2倍时间校正的情况下:
\(D = -\frac{3}{4} \times \frac{3}{8}ln(1 - \frac{4}{3}d) = -\frac{9}{32} ln(1 - \frac{4}{3}d)\)
上面这一版本看上去更加「准确」,然而实际上和我们最常看到的版本有什么差别吗?差别只是scale,只不过是乘以不同的常数而已,所以在我们比较不同序列的时候,完全是没有影响的。我们想要的不同直接去估计在某个时间段里发生突变的实际数字,而是一个距离的度量可以正比例于突变概率和时间,线性相关才是最重要的,至于斜率多大,反而是其次。