
拼图?我掐指一算,发现事情没那么简单!
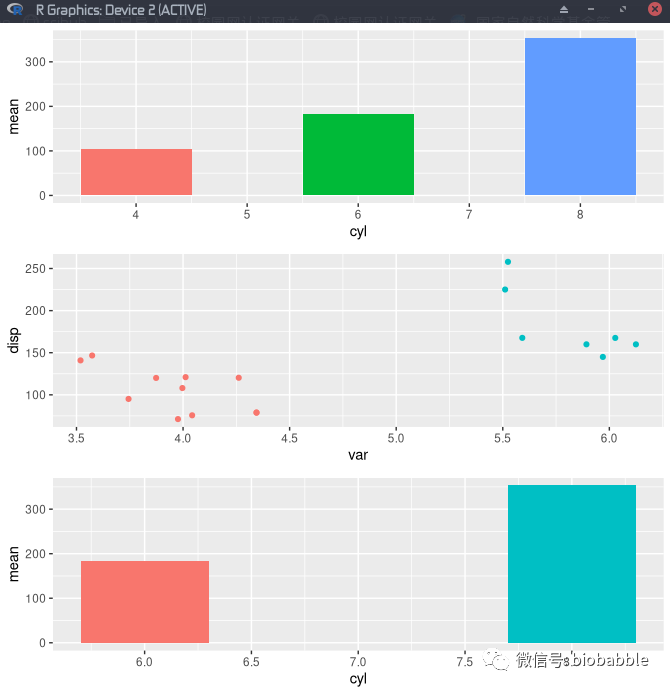
拼图很容易,像上面这张图,就是三张图拼在一起,但你仔细看一下,这结果可能不是你想要的,如果我们想要坐标轴按照值的大小对齐呢?
首先来一段产生上面图片的代码:
library(dplyr)
library(ggplot2)
library(ggstance)
library(ggtree)
library(cowplot)
no_legend=theme(legend.position='none')
d <- group_by(mtcars, cyl) %>% summarize(mean=mean(disp), sd=sd(disp))
d2 <- dplyr::filter(mtcars, cyl != 8) %>% rename(var = cyl)
p1 <- ggplot(d, aes(x=cyl, y=mean)) +
geom_col(aes(fill=factor(cyl)), width=1) +
no_legend
p2 <- ggplot(d2, aes(var, disp)) +
geom_jitter(aes(color=factor(var)), width=.5) +
no_legend
p3 <- ggplot(filter(d, cyl != 4), aes(mean, cyl)) +
geom_colh(aes(fill=factor(cyl)), width=.6) +
coord_flip() + no_legend
pp <- list(p1, p2, p3)
plot_grid(plotlist=pp, ncol=1, align='v')
我确实是加了align=‘v’的,但就是不对齐!要对齐真的不容易,因为有两个因素在影响:
- 坐标轴的取值范围
- 画布的扩充区域
这两个因素必须要一致才好对齐。要搞也挺容易,标尺可以设定limits和expand两个参数,一次解决。要是使用xlim或ylim就只能解决第一部分。虽然有标记可以解决,但依然不容易啊。比如说p1的x轴取值是[4,8],我们设一下看看:
p1 + xlim(4,8)

4和8的柱子都不见了,为何?因为xlim会去过滤数据啊,柱子是用矩形画的,这矩形有四个点,比如以4为中心的这个矩形,4个点有两个小于4,两个大于4,那小于4的被xlim干掉了,矩形就画不出来了。然后我们试试用标尺,给它扩充一些区域:
p1 + scale_x_continuous(limits=c(4,8), expand=c(0, 1))

一方面确实如我们所想,x轴从[4,8]扩充到了[3,9],但柱子还是不见了,因为xlim先干事,干完再扩充,该没的还是没有了。
这告诉我们一个什么事情?我们不能简单地从这些输入的数据集中计算range,取个并集了事,这是第二点,做完第二点得搞一下第一点,才能统一。然后还有第三点,如果连续型的数值,第一点容易搞,把limit range变大一点,但如果是字符型的,想想都觉得好难!然后还有第四点,你的输入可能不是一个data.frame,比如ggtree的输入是一个树对象,还有各种封装的函数,你的输入可能进行了各种操作之后,才来画图,然后就算你拿到了最终画图的data.frame,你还得拿到映射关系,到底什么变量映射到坐标轴上,在这基础上,才能谈什么1,2,3点。
- 得先扩limits,再去卡limits!
- 要在几个图中统一limits,并不简单。
- 如果是字符型的变量,怎么搞1?
- 如果你根本不知道变量是啥!!!
总而言之,言而总之,这简单的问题一点都不简单!最主要是我现在造了一个轮子,于是我就给你谈各种你没有这个轮子很困难的场景,就像有了一个药之后,就大谈你好多病,得吃下这颗大力金刚丸一样。
我的解决方案就是在ggtree包中实现了xlim2和ylim2两个函数,像下面这种p + xlim2(p1),它干的事情就是把p的x轴值域设为和p1一样。如果p是翻转过坐标轴的,会去设置它的y轴。
pp2 <- lapply(pp, function(p) p + xlim2(p1))
plot_grid(plotlist=pp2, ncol=1, align='v')

现在我们再看,对齐了!如果这些子图的数据都是不全的,我们并不是以一个图来设置值域,而是以它们值域的并集来做,这时候,你可以传入limits参数,这种情况,基本上就相当于你在用xlim和ylim。
pp3 <- lapply(pp, function(p) p + xlim2(limits=c(3, 11)))
plot_grid(plotlist=pp3, ncol=1, align='v')

xlim2和ylim2最主要的一点,就是让你用一个图做为参照,方便你让其它图和它对齐。下面通过ggtree的例子来讲一下ylim2。和进化树拼图,在《用散点可视化一个矩阵》一文是有讲过的,不过那个例子,值域是一样的,假设像上面的例子中有缺失值,还得吃现在造的药丸。下面的例子中,d1的信息就不全,而且有对不上号的row。
library(ggplot2)
library(ggtree)
set.seed(2019-10-31)
tr <- rtree(10)
d1 <- data.frame(
# only some labels match
label = c(tr$tip.label[sample(5, 5)], "A"),
value = sample(1:6, 6))
d2 <- data.frame(
label = rep(tr$tip.label, 5),
category = rep(LETTERS[1:5], each=10),
value = rnorm(50, 0, 3))
g <- ggtree(tr) + geom_tiplab(align=TRUE)
我们可以使用tidytree包实现的dplyr动词来操作ggtree对象,然后就可以把相应的y值给加上,用来画图。
library(dplyr)
library(tidytree)
d <- filter(g, isTip) %>% select(c(label, y))
dd1 <- left_join(d1, d, by='label')
dd2 <- left_join(d2, d, by='label')
p1画一个柱状图,p2画热图:
p1 <- ggplot(dd1, aes(y, value)) + geom_col(aes(fill=label)) +
coord_flip() + theme_tree2() + theme(legend.position='none')
p2 <- ggplot(dd2, aes(x=category, y=y)) +
geom_tile(aes(fill=value)) + scale_fill_viridis_c() +
theme_tree2() + theme(legend.position='none')
如果我们正常拼,就会像开篇的图一样,是对不上的,这时候我们就拿出ylim2,让其它图都和进化树对齐,然后再拼,完美!在拼图的时候,有参照的情况下,xlim2和ylim2就是这么方便:
p1 <- p1 + ylim2(g)
p2 <- p2 + ylim2(g)
library(cowplot)
plot_grid(g, p1, p2, ncol=3, align='h',
labels=LETTERS[1:3], rel_widths = c(1, .5, .8))

你可以把开头的例子改一下,把aes(x=cyl)改成aes(x=as.character(cyl))或者aes(x=factor(cyl))试试,xlim2和ylim2一样是OK的。可以应对前面谈到的1,2,3,4四个点。
