听说你也在画dotplot,但是我不服!
陈同的‘生信宝典’公众号出了篇《R语言学习 - 富集分析泡泡图》,搞个shell脚本,一步绘图。讲了这个脚本可以适用于clusterProfiler和其它软件的富集结果。
浑身都是硬伤,我都不想吐槽,但由于作者邀请我提点,那就吐槽模式全开。
一个command出图,小白已经哭晕
从出的图看,应该是ggplot2画的(就算猜错,要吐槽的依然正确),小白在web-server上做了分析,存结果为xls文件,拿你这脚本,一跑报错。读xls文件(别告诉我你跟用户说读xls但其实是个tsv)和画图的依赖关系没解决!用户友好在那里?不要告诉我你的脚本0依赖,有个shell就能跑,即使我们熟悉的各种命令,很多都是独立程序,不关shell什么事。
所谓的一步出图
既然讲了clusterProfiler,那么clusterProfiler用户笑而不语了。我们用dotplot不也是一条命令出图,为什么要退出R,去跑你的shell脚本,这过程还得转换数据,存储数据。最后的这一步,是前面+N步为代价的。
一步出图是邪恶的!
做为ggplot2画的图,我们用clusterProfiler的dotplot,写文件前,可以先看一下,做点调整。你搞个脚本缺少了用户互动的重要一步。
生物狗开口闭口都是next generation。画图也是二代了好么!一步出图是第一代产品,因为你只有纸笔模式,画完就完事了,那是死图,你想改,illustrator啊!
现在这年代,图已经不能简单地称为图,都是数据,只有在需要渲染图片时才是死图,做为数据,你是可以改的,改完再渲染,效果就变了。你用着二代产品,却在干一代产品的活,能不邪恶吗?
比如下面这个:
library(clusterProfiler)
data(gcSample)
x <- compareCluster(gcSample, 'enrichDO')
p <- dotplot(x, showCategory=10)
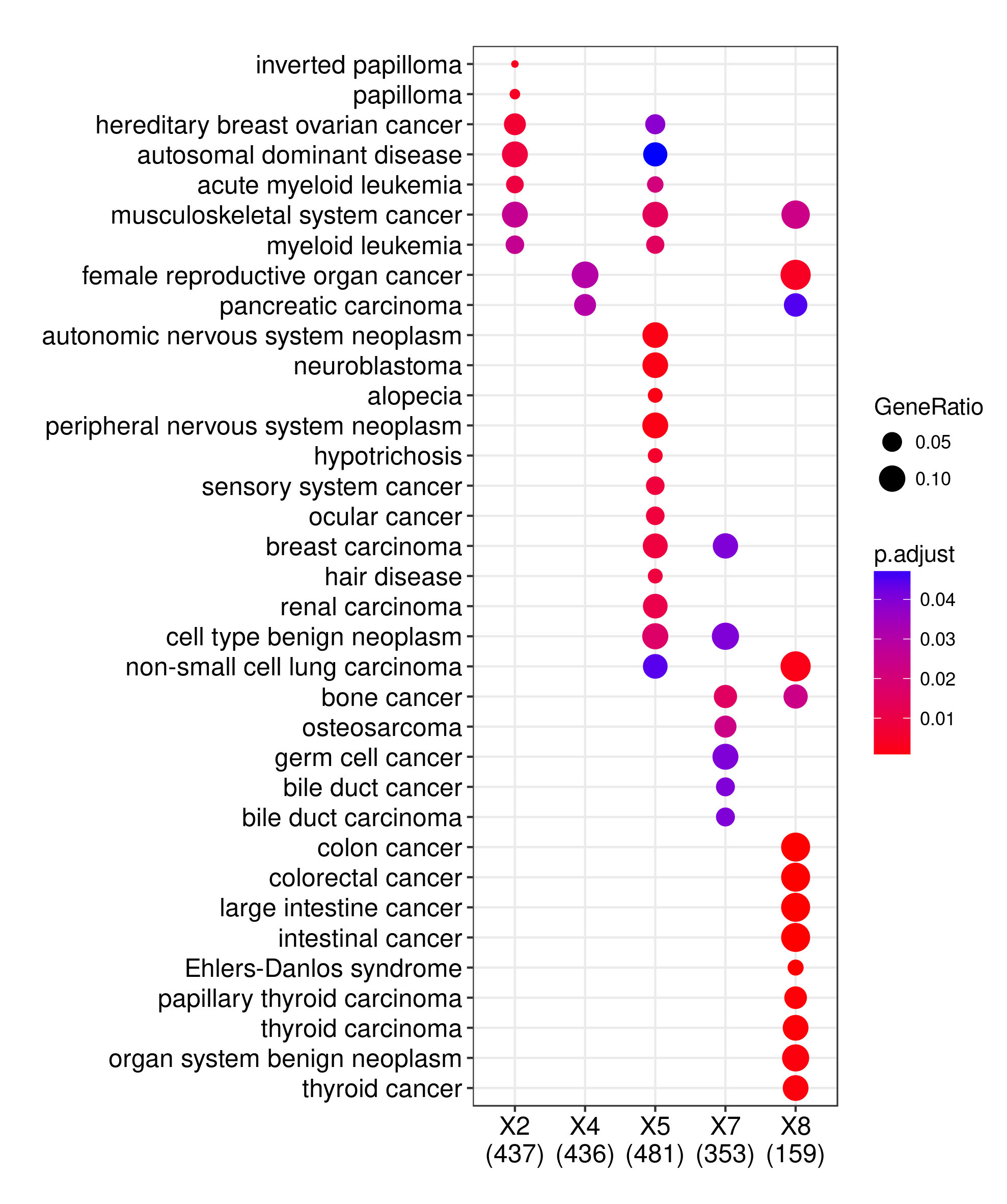
clusterProfiler出的图,我们可以随意改啊,比如改颜色:
p2 <- p + scale_color_continuous(low='purple', high='green')
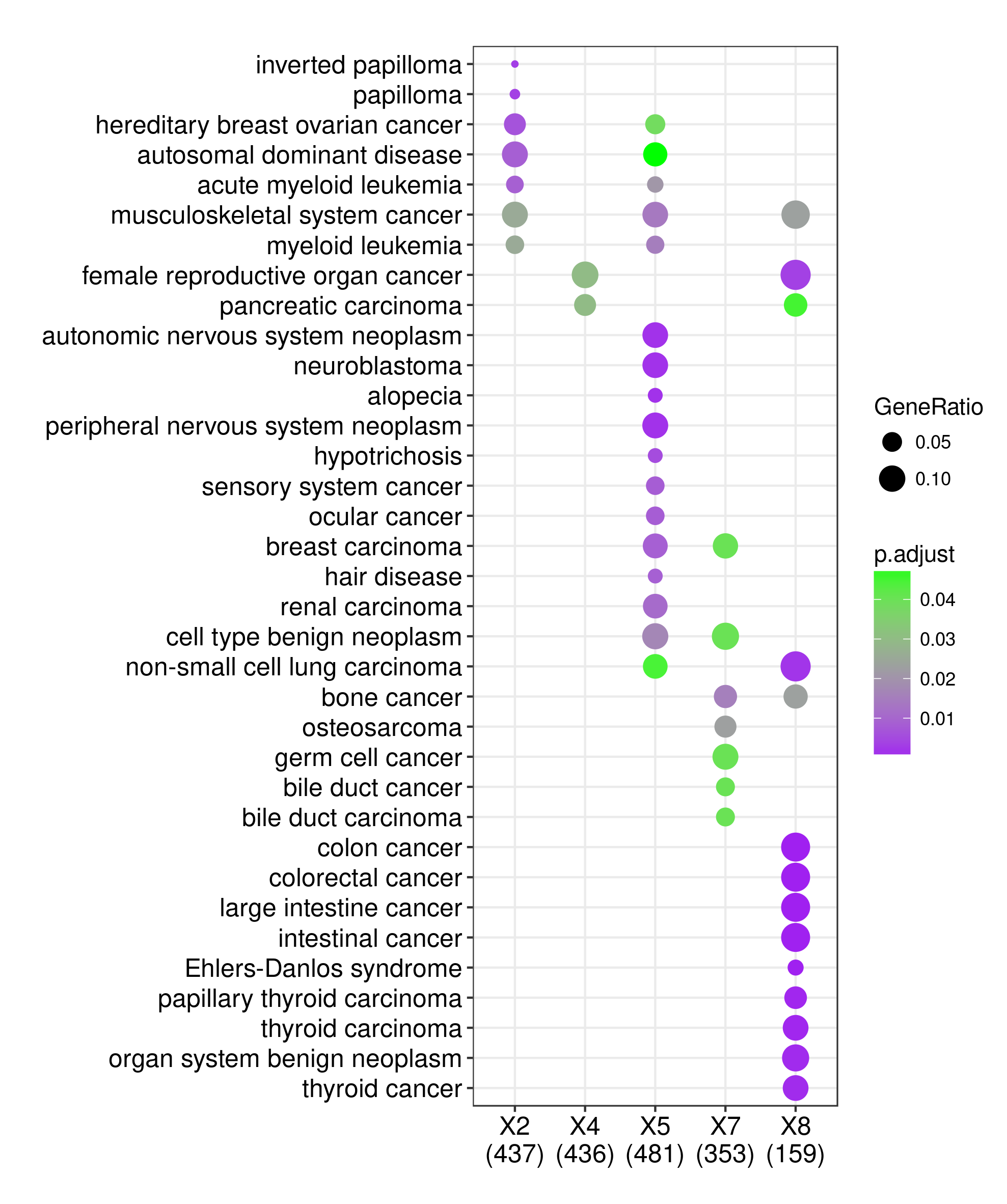
再比如改点的形状:
p2 + aes(shape=GeneRatio > 0.1)
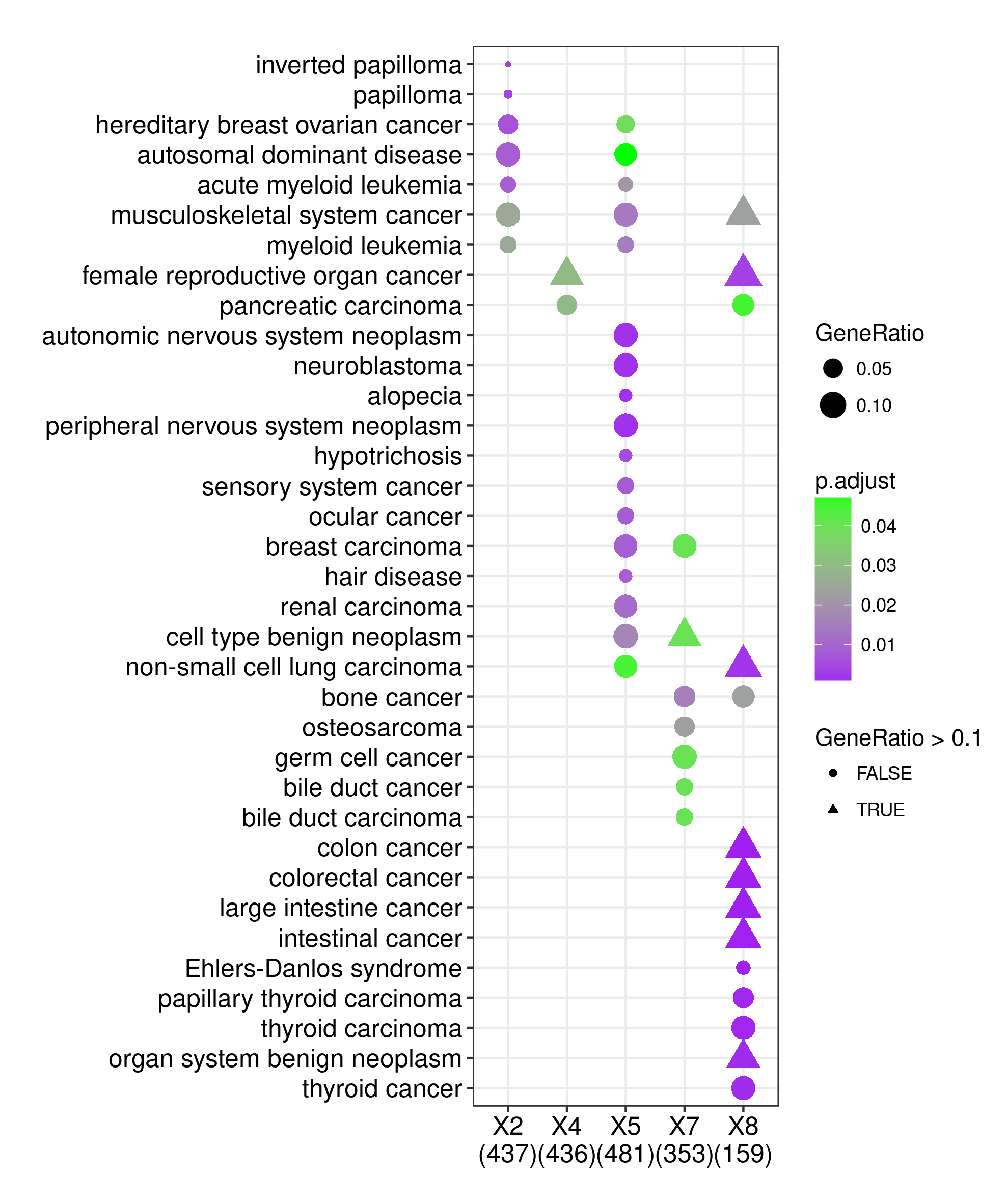
比如字体溢出、长文本截断、设置点的大小等等都可以搞,你还可以改图例,改背景等各种元素等等!
我所说的硬伤
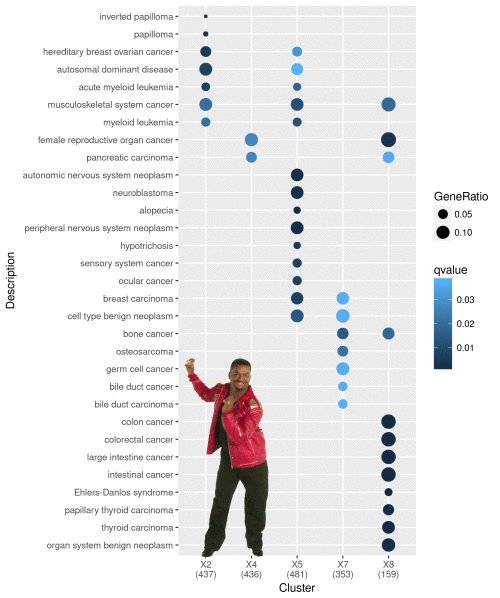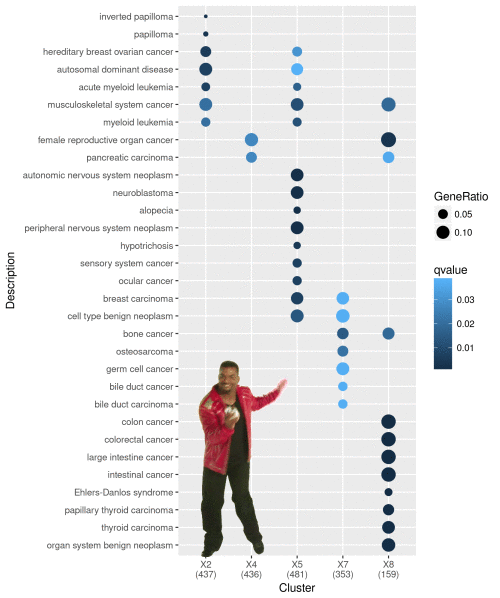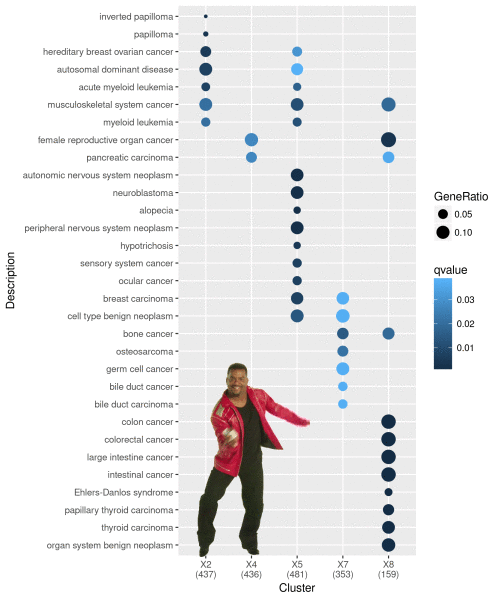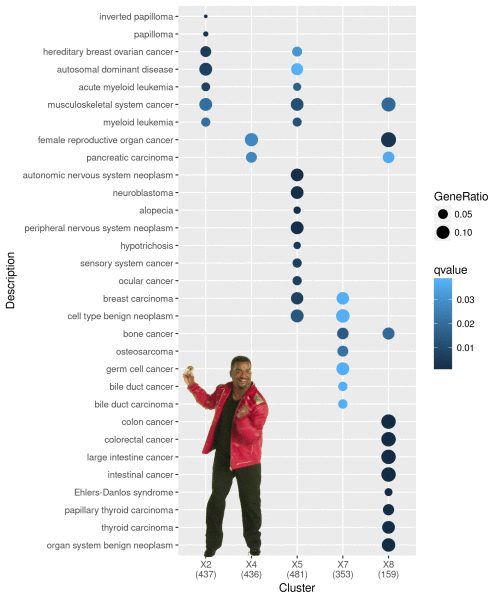
下面是陈同原文里的图:
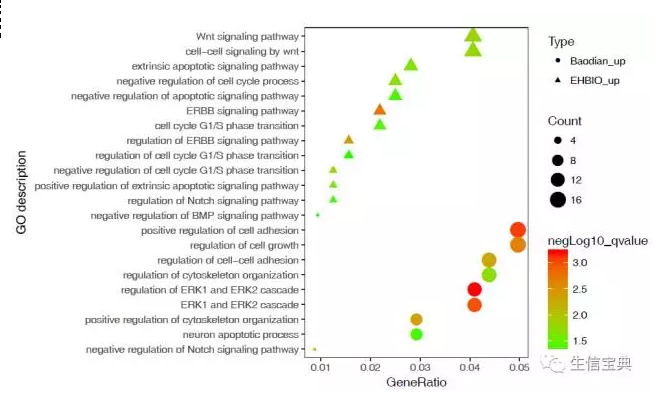
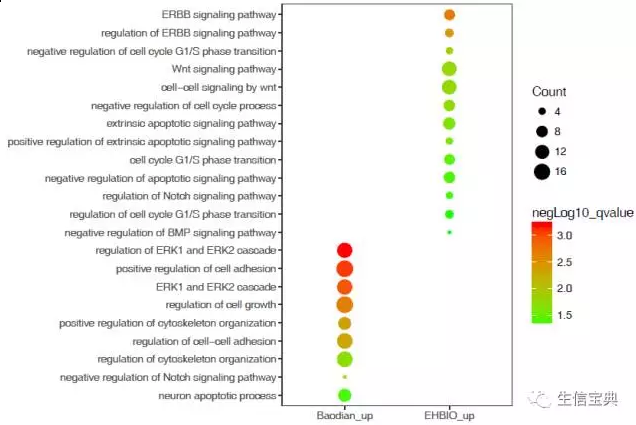
我当时看了说硬伤,告诉他没overlap,他不明白,请我详细讲,于是有本文。
他上面的图是给人的感觉就是两组实验非常不同,完全没有overlap,但实际并非如此,只是我们没办法把所有富集结果展示出来而已,只展示了最显著的一部分。然而我们在截取最显著的部分时,应该把其它组实验中有overlap的结果也截出来,这个在我讲解showCategory参数中已经有明显明确说明。
最后来两个硬广, 硬广一
对于富集结果没办法完全展示这个问题,我们会发现最显著的那些,其实都overlap了很多基因,特别是GO的分析结果,GO的冗余太多,clusterProfiler提供了simplify函数,可以去冗余哟,让我们解析结果更容易,这个后面也会介绍。
硬广二
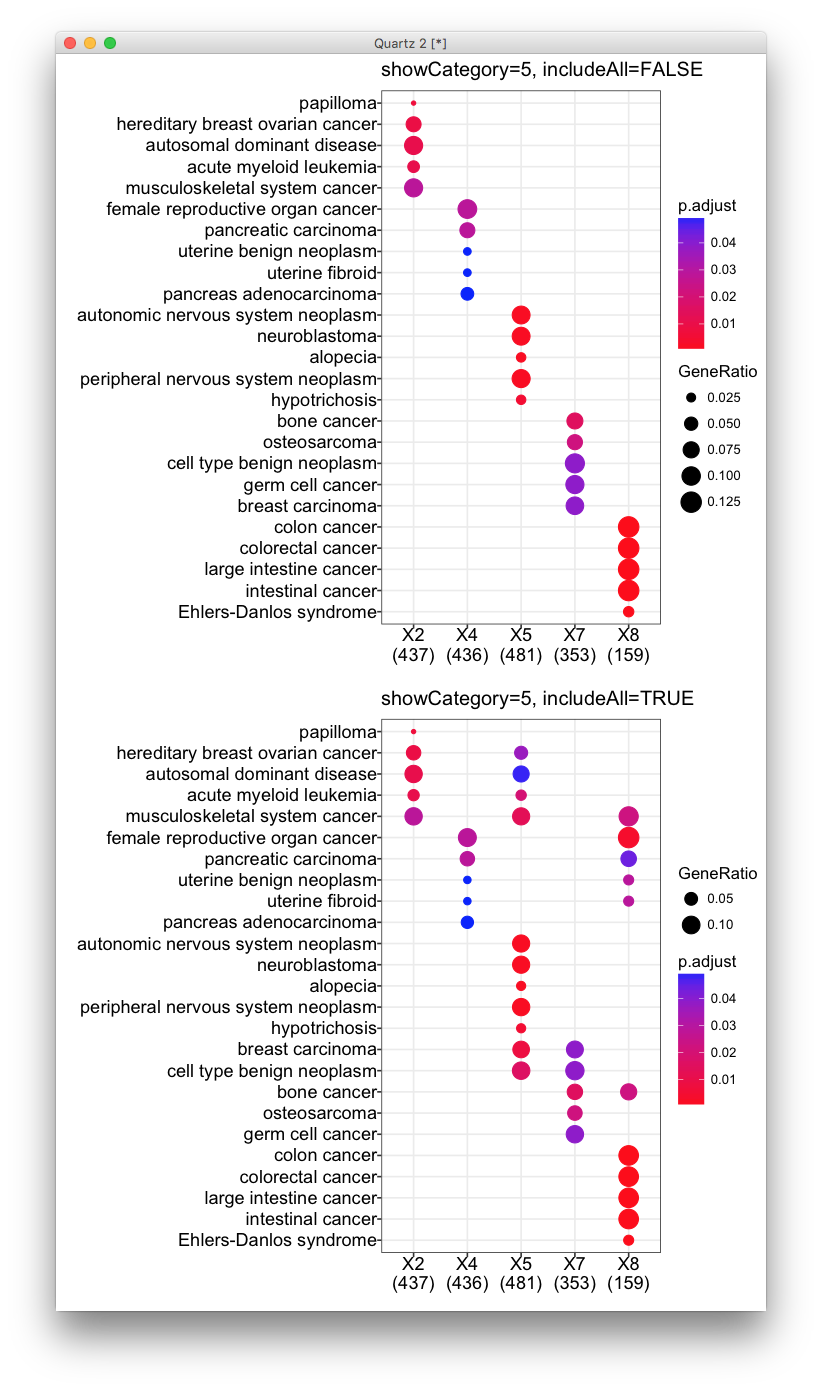
有些人就喜欢自己用ggplot2画,可能觉得透明吧,自己搞有逼格吧。氮素像上面的槽点,像这个includeAll的参数,在把clusterProfiler的结果转变成data.frame后进行处理的时候,你是否能够考虑到?我见过太多自己画的,都是不同实验组给人一种绝然不同富集结果的错觉。
然而我写的代码,模块化非常好,数据处理和可视化是分开的,clusterProfiler的输出你不用as.data.frame,就可以直接传给ggplot2,别的富集软件做的,不是data.frame对象的,都不能传给ggplot2,但clusterProfiler可以,如果你想问为什么,原因只有一个,因为那是我写的!clusterProfiler的dotplot所有参数,都可以传给ggplot2,像上面用到的showCategory, includeAll这些都可以,然后数据处理于无形中,你可以加图层自己画图了。这个功能存在了好几年,只不过我第一次公开讲。
ggplot(x, aes(Cluster, Description), showCategory=8) +
geom_point(aes(color=qvalue, size=GeneRatio))