
Hi Guangchuang,
Is there a way to control annotations in the the annotatePeak function? For instance I would like to ignore “downstream” and consider those peaks “intergenic”. Or for instance combine “1st exon” with “other exon” so there is one category of “exon”.
Any help would be great, thanks for doing this!
-Andrew
首先基因下游是什么?
我们知道上游很重要啊,因为可能会调控转录,但注释的时候,没有上游这个东西,为什么呢?因为转录起始位点TSS的上下游被定义为promoter,所以啊上游被包括在promoter中,也就没有上游这个category了。
ChIPseeker系列传送门
- CS0: ChIPseq从入门到放弃
- CS1: ChIPseq简介
- CS2: BED文件
- CS3: peak注释
- CS4:关于ChIPseq注释的几个问题
- CS5: 吃着火锅,唱着歌,还把分析给做了
- CS6: ChIPseeker的可视化方法(中秋节的视觉饕餮)
- CS7:Genomic coordination的富集性分析(1)
- CS8:Genomic coordination的富集性分析(2)
- CS9: GEO数据挖掘
ChIPseeker这个系列,从《CS0: ChIPseq从入门到放弃》到现在CS10,总共11篇,第一篇以八卦开始,我想很有必要以八卦来结束。
ChIPseeker系列文章已经介绍了很多内容,包括注释的方方面面,也包括强大的可视化功能(《CS6: ChIPseeker的可视化方法(中秋节的视觉饕餮)》)。
今天要介绍一下数据挖掘,从大量已有的数据来产生新的hypothesis。正如我在ChIPseeker的文章里写的:
There are increasing evidences shown that combinations of TFs are important for regulating gene expression (Perez-Pinera et al., 2013; Zhu et al., 2008). However, systematically identification of TF interactions by ChIP-seq is still not available. Even if a specific TF binding is essential for a particular regulation was known, we do not have prior knowledge of all its co-factors. There are no systematic strategies available to identified un-known co-factors by ChIP- seq.
并没有方法可以大规模地预测未知的共同调控因子,而数据挖掘就是要给我们这种预测的能力。
我当年在写ChIPseeker的时候,我有纠结是写篇Bioinformatics的application note呢,还是写篇长文灌水NAR,毕竟NAR影响因子高一点,最后还是发了Bioinformatics,因为我没钱,囧,Bioinformatics不要版面费啊。然后限于篇幅,ChIPseeker有大量可视化的函数,我在文章中一张图都没放!!!如果当时决定发NAR的话,这个数据挖掘这一块我就会写多点。
在《CS7:Genomic coordination的富集性分析(1)》说到了seq2pathway这个包,其实是两部曲,seq2gene->gene2pathway,无非是把测序片段用临近的基因注释,包括和TSS overlap的基因,宿主基因,上下游的基因等,然后拿这些基因跑ORA,做富集,仅此而已,这个包支持的物种极有限,《CS4:关于ChIPseq注释的几个问题》这一文中讲到ChIPseeker支持所有有基因组注释的物种,而《clusterProfiler for enrichment analysis》也支持所有物种(即使你自己跑的电子注释,也能支持),那么使用ChIPseeker来做基因注释,然后衔接clusterProfiler就可以支持所有物种的测序片段进行功能富集分析了。
《CS3: peak注释》本身就支持几种注释,另外我写了一个seq2gene的函数,套用seq2pathway的思路,把一个基因位置上所有关联的基因全部返回来,我们可以使用它去把基因位置信息转换成基因列表,然后用于富集分析,还是熟悉的味道,还是熟悉的配方🦄
2017眼看要结束,立下写《CS0: ChIPseq从入门到放弃》的flag还没完成,当时ChIPseeker是33个引用,现在已经80了,时间过得好快。
最近放羊的Jimmy给我发来了一个截屏:
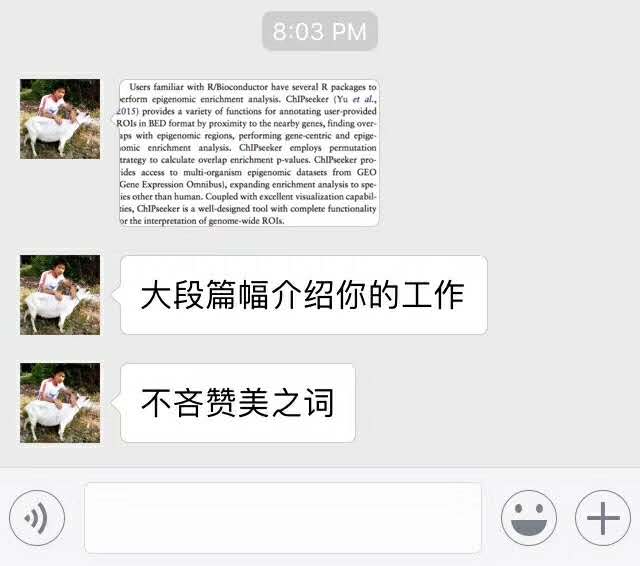
说了一篇新文章,大段在称赞ChIPseeker:
这篇文章介绍如果把ChIPseeker搬上galaxy,和galaxy上其它软件一起拼成流程,跑一个ChIPseq注释的流程,从fastq文件开始,比对生成bam文件,peak calling生成bed文件,基因组注释,一个完整的流程,这个流程一旦设置好,每次跑都只是点点鼠标就可以了。 本文额外附送: 1. 如何把R程序变成命令行程序 2. 如何把命令行程序搬上galaxy (知名的程序都有人搬好,但自己的程序还是需要学一下怎么配置的)
Galaxy可以说是低端生信从业者杀手,如果你的能力只是跑跑流程,galaxy完全可以取代你的工作。
如果你是苦逼的生物研究生,苦于要自己分析数据,不会跑命令行程序,对各种参数表示晕菜,galaxy也是拯救你的神器,如同有个做生信的人在旁边帮助你,参数你点点菜单就可以了,跟程序变运行又可以了,流程自己都可以设计并一键运行。
安装galaxy
- requirements: python 2.7 and git
- only three steps
克隆galaxy项目
git clone https://github.com/galaxyproject/galaxy/
cd galaxy
## switch to master branch, stable release
git checkout -b master origin/master


