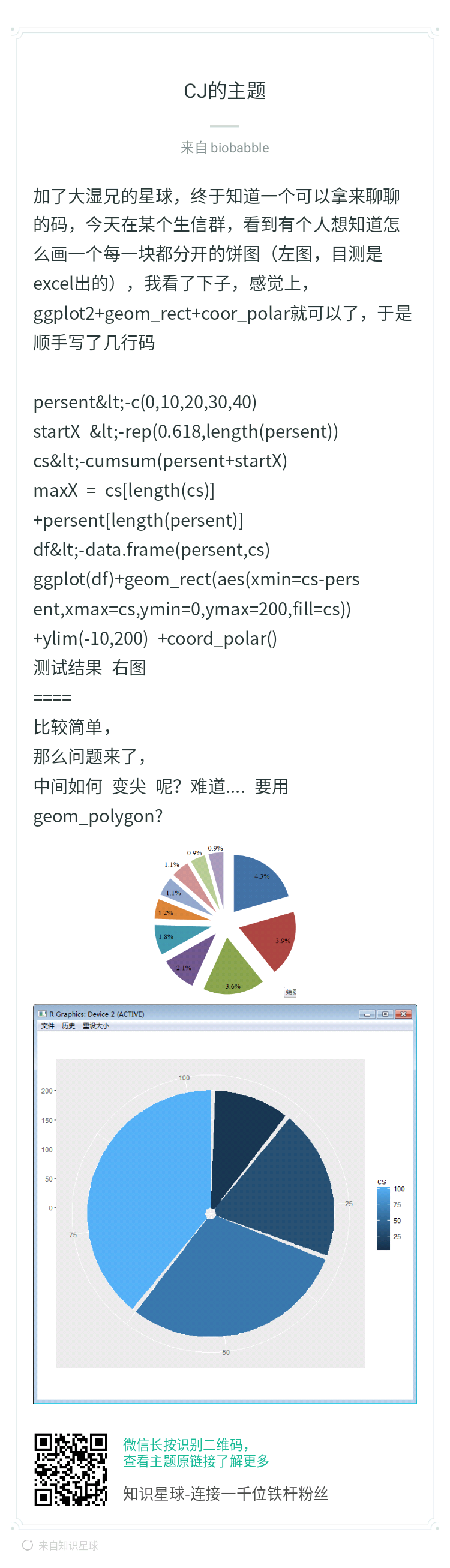
这是CJ在我的星球里分享的一个关于饼图的实现方式,代码的排版太差,还有一点是对于普通用户来说,还是有点难度,如果是我,必须是写成函数,直接出图。

《ggplot2字体溢出的那点破事》这是经典老问题了,现在新版本的ggplot2有新的解决方案了,在coord_cartesian中新加入了clip参数,这样可以支持把图层画在画布之外,那么文本打过界也就支持了。这有一个好处,是可以支持direct label,而不需要调整xlim和ylim,毕竟你把xlim和ylim搞大有时候会给人以误导,认为你的数据取值范围就是图中的xlim和ylim,但实际上要小一些。
我以ggtree为例,为了让tip label打全,那么p1把时间给搞到2020,但实际上最近的采样时间是2013年,这样你单看x轴的标记,总感觉有一点点不对路,或者有一点点别扭。现在好了,我不设置xlim,而是让label打过界,当然还是需要有足够的空间来放这些文本,这个可以通过把margin搞大来实现。
R 3.5.0已经发布了,我昨天已经更新了,Bioconductor也将在5月初发布3.7版本,就我个人而言,新版的Bioconductor主要有以下一些新东西:
新包enrichplot,《enrichplot: 让你们对clusterProfiler系列包无法自拔
》,以后clusterProfiler系列出图更好看了,而且所有图你都可以用cowplot拼图。
这是去年「知识星球」里的提问,「知识星球」相当于是众筹我一年的时间,向我提问,请谨慎入坑。
我当时就写了一个函数ggvenn,这个函数其实包装了venneuler,但由于venneuler依赖rJava,而很多小伙伴不会装rJava,而因此装不了yyplot,所以我去掉了这个依赖,但如果你想要用ggvenn这个函数,请自行安装rJava和venneuler。其实还有另外一个包,VennDiagram,它的输出是gList,所以可以直接封装为ggplot2图层,然而对于画venn plot,我并没有太多的兴趣,《CS6: ChIPseeker的可视化方法(中秋节的视觉饕餮)》一文中介绍的upset plot,可能更好一些。
require(ggplot2)
p <- ggplot(iris) + aes(x = Sepal.Length, y = Sepal.Width, color=Species) +
geom_point(size=5) + theme_classic()
首先我们有一个图,是用ggplot2画的,上面这图大家太熟悉,不打印出来都知道是什么了。
我在最新版的ggimage中加入了一个ggbackground的函数,我随便从网上找一张iris的图片,我们把p和img同时传给ggbackground就好了,非常容易,于是图的内容还是一样,但加了一张我们给定的图片做为背景。
require(ggimage)
img = "https://assets.bakker.com/ProductPics/560x676/10028-00-BAKI_20170109094316.jpg"
ggbackground(p, img)
4月3号发了以下一条文字推送:
遇到辣鸡导师,只有三个字,忍滚狠,我选择滚,考博期间,发现人品不好,我选择滚,《来香港读博其实是被逼的》,读博期间,本着就是退学也要滚的心态,把导师给炒了,《CS10: 八卦终结版》,忍下来也会消磨掉你所有追求/理想,比狠的话,如果没有压制对方的渠道,对于这种势力严重不均衡的情况似乎不太现实,所以我奉劝大家,滚!一两年的沉没时间,放长远了看,根本不算什么,要勇于放弃,滚的远远的
使用barplot来展示富集分析结果是很常用的,而dotplot比较barplot来说,多了一个点大小的信息,可以比barplot展示多一个信息,所以是比较推荐的,我之前已经写了《dotplot展示富集分析结果》和《dotplot for GSEA》两篇文章,dotplot虽然简单,很多人会觉得会容易用ggplot2画出来,但其实有些细节,比如《为什么画出来的点比指定的数目要多?》,有些技巧,比如《搞大你的点,让我们画真正的气泡图》,是很多新手所不具备的,图虽然简单,但老司机的飚车技能也不可小看哦,所以我在《听说你也在画dotplot,但是我不服!》的文后就说了一句话:
clusterProfiler之所以好,因为真的考虑了很多细节!请放开那图,让clusterProfiler来画!


